- How to design an interoperable storage-oriented blockchain
- The missing link in decentralized storage
- The StorageHub vision: interoperable decentralized storage
- Decentralized storage design process
- Field research: decentralized storage providers comparison
- Which decentralized storage demand is being met?
- Divergent phase: exploring all possibilities
- Convergent phase: cohesive streamlining
- Decentralized storage design proposals
- Protocol Interaction
- Providers Interaction
- Conclusion
How to design an interoperable storage-oriented blockchain
The Web3 world was born with a focus on decentralizing the networks that bind us together, revolutionizing the way we connect. This paradigm shift began with Bitcoin, which introduced a novel way of providing a secure, transparent way of processing and storing transactional information between individuals independent of any central entity.
Progress did not stop there, and with the birth of Ethereum came the idea of decentralizing computation, thus giving rise to the world’s first global computer. As more advances were made, the functionality of this technology increased. With the emergence of Polkadot, the possibility of interconnecting the different blockchains in existence, which addressed one of the biggest challenges in the industry – interoperability amongst different blockchains. Prior to Polkadot, blockchains operated in silos serving a specific purpose but unable to communicate or transfer data amongst one another. A network’s capabilities were confined within its own ecosystem. Polkadot gives blockchains the chance of specializing their uses to make the entire Web3 ecosystem more versatile.
All these advances were mainly focused on transactional information, consensus mechanisms and smart contracts; but the same versatility in use cases generated more demands. The emergence of dApps, NFTs, or even on-chain and verifiable machine learning models via zk-proofs, made the need for medium to large scale forms of decentralized storage more and more important.
Blockchain technology is renowned at its core for the ability to provide a secure and transparent ledger system to maintain a decentralized record of valuable information, such as transactions and balances. However, as blockchain technology continues to mature and diversify, there is a need to leverage blockchain for more than just transactional data. Emerging use-cases are proving the need for greater storage needs in the space. Enter projects like Filecoin, Arweave, and BNB Greenfield among others.
The missing link in decentralized storage
The central complication with today’s decentralized storage solutions is that they operate as standalone blockchains. This means that a dApp requiring both the ability to compute logic via smart contracts and to have substantial storage, must effectively manage interactions with two separate solutions: one blockchain that provides the computation (e.g. Ethereum, L2 rollups, parachains) and the other dedicated to storage.
Currently, this occurs when smart contracts on certain L1s that have a URL pointing, for example, to a NFT stored on Arweave. Again, the problem is that there is no interconnection between the two. Let’s imagine a few possibilities:
- What if the dApp could natively request more storage space, or delete it?
- What if the contract could update access and ownership of the data itself?
- What if the contract could read and act on the stored data?
Simple functionality like this would open up a whole range of new scenarios.
Polkadot’s work over the past few years to interconnect different blockchains truly stands out in this context. A storage parachain in the Polkadot ecosystem presents a unique value proposition by offering services to other parachains. This could allow dApp developers building on top of them to benefit from a seamless integration, effectively abstracting them from the complexities and inefficiencies of the dual solution.
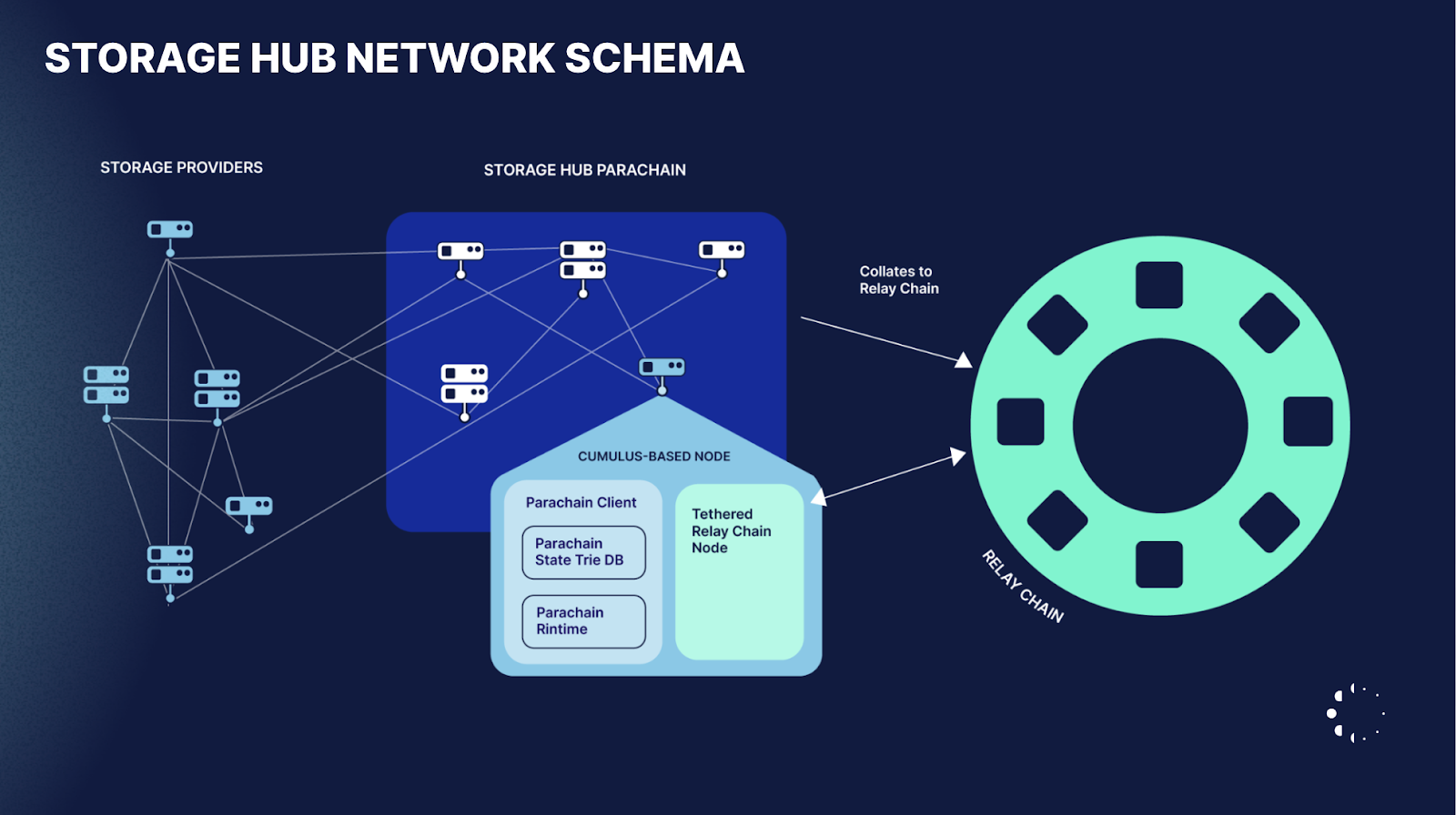
The StorageHub vision: interoperable decentralized storage
Building upon Polkadot’s strides in interoperability, StorageHub is a storage optimized parachain designed to work with other Polkadot & Kusama parachains. It focuses on storing data in an efficient and decentralized way. StorageHub enables other parachains within the ecosystem to seamlessly access, utilize, and manage this storage. It will be possible for users to directly interact with the storage on-chain, but StorageHub also seeks to natively interoperate with existing parachains via cross-chain messaging (XCM).
Decentralized storage design process
Well, great. The first phase of any design process is complete: a clear direction of what we are aiming for. Now it’s time to dig deeper. Although it may seem obvious, the next step when starting to design and develop a product is to investigate similar solutions, that is:
- What is their value proposition? What is it that sets them apart?
- What is their high-level architecture?
- What problems have they encountered and how did they solve them (or not)?
Additionally, understanding limitations provides invaluable insight into potential improvement areas and market gaps.
This process is very important because it allows us to learn from past experiences: take parts that have worked well, anticipate possible problems they have had, take inspiration from some parts of a project and combine them with other parts of another. All this allows us to think of new designs that are better adapted to the specific needs of the system being built. For this research we focused primarily on Arweave, Filecoin and Greenfield BNB.
Field research: decentralized storage providers comparison
As we embarked on the research phase, the first one we examined was Arweave. We were particularly intrigued by the possibility of one time payment for perpetual data storage. Their approach involves calculating the present value of the cost flow required to store a given amount of data indefinitely, a financial concept known as ‘perpetuity’. This calculation also includes the assumption that storage costs will continue to decrease exponentially over time. Understanding the mechanics, especially the incentives of this model, were a key focus. While exploring Arwave’s innovative framework, we quickly realized that StorageHub had very different requirements and steered our research to align more closely with our unique needs and objectives. Which included:
- We need to have the ability for it to be private.
- The storage should be able to be removed if it is no longer required.
And the latter makes the network incentives change completely, structurally changing the network accordingly.
We continued the research with Filecoin, where we were immediately impressed at the advanced cryptographic technology they developed for storage verification. But what is the need to develop the tech in the first place? Well, what happens in a storage blockchain is that, unlike Bitcoin or Ethereum, the data cannot be on-chain. The size of the files stored possess a significant challenge. Imagine a single file containing the entirety of Bitcoin’s transaction, there is no other way to store that other than to store the data off-chain. But then, what is on-chain? Filecoin proposes that deals between users and storage providers have to be on the blockchain. And after a deal is proposed, the user will send the data to the provider. The provider then has to send periodic storage proofs to corroborate that it is still storing the information. These proofs are also stored on-chain.
Some of the key points of the Filecoin proving system are:
- Storage providers have the data divided into sectors that range in size from 32 to 64 gb. A sector is the default storage unit that miners put on the network.
- Each sector is a contiguous array of bytes that a storage provider puts together, seals, and performs proofs of storage on. The sealing is a computationally intensive process performed on a sector that results in a unique representation of it.
- Once the sealing process is completed, storage providers can provide Proof of Replication. PoRep is cryptographic proof that a storage provider has stored a unique copy of a piece of data. This guarantees that SPs actually allocate and dedicate storage space instead of pretending to do so.
- After Proof of replication, the storage provider will be requested to periodically submit Proofs of Spacetime, to prove that the data is still stored over a period of time.
Finally, we looked in depth at BNB Greenfield, which played a crucial role in addressing challenges associated with designing a protocol for data retrieval. This exploration help us resolving a critical issue: how to verify and prove the successful completion of data retrieval, which is a fundamental aspect of ensuring efficient and reliable access to stored information
In essence, BNB Greenfield comprises two types of storage providers: primary and secondary. Primary providers can set their storage prices and offer a differentiated service. This allows users to choose their preferred storage provider. On the other hand, secondary providers are responsible for providing redundancy to the network. Each of them stores a data chunk, utilizing Erasure Coding of 4+2 for robustness.
The intricacy of data retrieval is that, as it is an off-chain process (since the storage itself is off-chain) it is very complicated to think of a system or protocol that proves that the data transfer occurred. And what is even more complicated is that this system needs to be resistant to both the storage provider or the user being malicious. For example, the provider might simply want to censor the user by not returning the data it stored (although the provider might indeed have it stored, and thus continue to provide proof of storage). Or the user could, after receiving the data, claim that it was never transferred to them.
At BNB Greenfield, storage providers are incentivized to behave correctly, because if they don’t, users will simply choose another Storage provider. In this way, primary providers that do not perform as expected will be de-selected.
Which decentralized storage demand is being met?
Taking the wealth of information gathered from the experiences of the current decentralized storage solutions in the space, we are able to learn and we can start thinking about our particular case.
When starting to design any system or product, let’s take a look at the questions to ask:
- Who is going to use my system?
- What are the minimum requirements that my system has to have? In other words, what demands does my system have to satisfy?
These were the first questions we asked ourselves when we started thinking about what StorageHub should look like. As a given, we knew that the Web 3 Foundation wanted to support our vision: to give storage to applications running on Parachains / Smart Contracts in the Polkadot ecosystem, interacting natively through XCM.
Could we be more specific in identifying the use cases of our decentralized storage solution? Is there a specific parachain or application in the Polkadot ecosystem that requires a solution like ours? Should we “manufacture” that first use case leveraging Moonbeam? Answering these questions is critical, as it would not only provide a practical demonstration of our solution’s efficacy but also validate its necessity in a real world context- specifically within the Polkadot network.
Recognizing and answering those questions, will help to drive the whole design to solve the specific problems of that particular use case. For example, there could be a decentralized social networking protocol, or simply a need to store NFTs or perhaps developing a system to store runtimes so that Coretime can run them on demand without the relay chain validators having to keep them in their storage.
By resolving these initial inquiries, it enables us to explore further aspects such as:
- What is the size of the data we should store? If it is too small, we could even think about on-chain storage.
- Should the data be mutable or immutable? Depending on this, we could define whether to use content-addressing or location-addressing.
Interestingly enough, we discovered that there wasn’t a specifically outlined use case provided by the Web3 Foundation, other than providing a decentralized and native storage service for Polkadot. This opened up a realm of possibilities for us to define to be able to carve out a unique niche within the network.
Divergent phase: exploring all possibilities
To solve this, the first approach we took was to first list all the questions/requirements we could think of, look at possible decentralized storage solutions, and then analyze their pros and cons. The idea of this was to start a “divergent” process in which we tried to be open to all possibilities, to think of all potential requirements/use cases.
This approach led us to an extensive phase of inquiry and exploration where we began to research and answer questions like the following:
- Should data be stored on-chain or off-chain? Naturally, the latter adds more value and use cases, as it allows storing large files that would be highly inefficient or impossible to store on-chain. However, it also makes it more challenging to provide guarantees about data availability and the security of the stored data.
- Storage proofs. If data is stored off-chain, how can a storage provider (a server storing data off-chain) demonstrate that it continues to store the committed data?
- Game Theory. How can the system offer a set of incentives that naturally align the actors participating in it with the interests of the system as a whole? One of the most obvious conclusions here is that storage providers should be compensated for the service they provide (i.e., for the data they store).
- How are permissions managed? In a decentralized system where data can be stored on many different servers, how is access control enforced?
- User interaction. In other words, who should the user interact with? Is the StorageHub a system that abstracts everything for the user? Or should the user be exposed to the entities involved in the StorageHub (such as storage providers) and make StorageHub the platform for that interaction to occur?
- How is storage pricing calculated? Should it be a price for the entire system, or should each storage provider set its own price?
- What is the best way to manage data recovery? Especially when it comes to off-chain data. Since data recovery involves transferring the correct data from the storage provider to the user, how can it be ensured that the recovery has been done correctly without trusting any of the parties involved?
- How are replicas managed? In other words, what is the degree of redundancy of the data stored in the StorageHub?
Going through this provides extreme value. The most important thing in this stage is to try to think of as many possible scenarios and investigate each of them. Tools such as brainstorming for the questions/requirements that such a system may need are very useful. If it is well done, at the end of the process the team ends up with a lot of knowledge that lays the groundwork for the next stage.
Convergent phase: cohesive streamlining
After a divergent process, where all the requirements and their possible implications are explored, the next step is to synthesize that knowledge into a few internally consistent solutions. And this is something that the divergent stage will naturally require. Why? Well, clearly some of these issues are related to each other. For example, you can’t talk about Game Theory and incentives without considering how price is calculated. Nor can one begin to think about decentralized storage incentives if it is not defined whether the protocol will completely abstract the user (i.e. storage providers would be chosen automatically), or whether the user is the one who chooses his provider because of some differential value proposition offered by the latters. Thinking about the interrelationships between these questions / requirements, enables one to see a complex web of dependencies.
That is why, after incorporating all the knowledge from the divergent stage, we decided to develop two coherent proposals. The key distinguishing factor for the two proposals was centered around how the user interacts with StorageHub.
Decentralized storage design proposals
Protocol Interaction
The system is designed in a manner in which the user is completely abstracted from the choice of storage providers for a given file. It focuses on decentralization, at the expense of ease of retrieval. Since storage providers are chosen pseudo-randomly, to maximize decentralization of the data, there is a challenge in providing strong incentives for that storage provider to make the data easily and reliably available. It is therefore needed to provide compensation for retrieval, resulting in the challenge of trustlessly proving the off-chain action of retrieving that file occurred. Besides data retrieval, focusing on decentralization means all storage providers should be treated as equal individuals, and so the system as a whole can only cater to the use-cases that the minimum requirements of a storage provider allow for. Should those requirements be high, it would also sacrifice decentralization.
Providers Interaction
If instead of decentralization, the goal is “unstoppability”, understood as no user/app should be locked in to a storage provider with their data, but always have the option to permissionlessly choose an alternative, there is now room for enhancing usability and increasing flexibility about use-cases, especially when it comes to data retrieval. In this model there is a distinction between two kinds of storage providers: Main and Backup. Main storage providers are responsible for offering data retrieval with unique value propositions, in an open market where users would choose one (or more) of them. Backup storage providers are there to guarantee unstoppability, and if the user wants to change to another Main storage provider, the data is always available for retrieval from the Backup providers. However, since the Backup storage providers are not required to offer user-facing retrieval, just occasional peer-to-peer retrieval for another Main storage provider, their operational costs can be significantly lower. On top of that, the system can treat them as equal individuals and be more decentralized. In other words, Backup storage providers provide unstoppability and reliability as a decentralized storage network, while Main storage providers offer convenient data retrieval and flexibility of use-cases.
Conclusion
Designing a system from scratch presents a formidable challenge. In order to achieve something big, it is always prudent to break down the process into smaller parts that will enable the ability to acquire more knowledge and, therefore, reduce uncertainty.
The overall process looks like:
- Define the general goal/vision for the system
- Research existing solutions that already solve similar problems
- Identify a target user. That is, to clearly understand the demands that your system is going to be satisfying.
- Brainstorm all the possible components required to satisfy those specific user demands.
- Converge on a couple of coherent solutions.
- Compare them and decide which you are going to build
- Thoroughly detail the the design
Curious as to why the final two steps of this process haven’t been discussed yet? The crucial stages will be covered in a subsequent post, in which we will detail our choice and the intricacies of our decentralized storage design.
In the meantime, you can learn more on our research process in the StorageHub Design Proposal on Github.